
6.2 Speech Perception
Speech perception is the process by which the sounds of language are heard, interpreted, and understood. The study of speech perception is closely linked to the fields of phonology and phonetics in linguistics as well as perception in cognitive psychology. Research in speech perception seeks to understand how human listeners recognize speech sounds and use this information to understand spoken language. Speech perception research has applications in building computer systems that can recognize speech, in improving speech recognition for hearing- and language-impaired listeners, and in foreign-language teaching.
The process of perceiving speech begins at the level of the sound signal and the process of audition. After processing the initial auditory signal, speech sounds are further processed to extract acoustic cues and phonetic information. This speech information can then be used for higher-level language processes, such as word recognition.
One challenging aspect of speech perception is the segmentation problem – we must somehow dissect a continuous speech signal into its component parts (e.g., phonemes, words). A second challenging aspect of speech perception is the lack of invariance problem – sounds are different in different contexts. For example, different people speak differently: speech sounds produced by men have very different frequencies from the sounds that children make, and even the sounds that two same-sex adults produce are quite different (i.e., people have different voices). Similarly, the sound of language spoken in a large auditorium is very different from the sound of language spoken in a laundry room.
Despite these problems, we still correctly identify speech sounds even when they vary dramatically from person to person and context to context. In fact, a child’s /u/ may may be acoustically very much like an adult’s /æ/, but no-one misperceives these sounds.
One might think that we can do this because, despite this variability, speech sounds are characterized by some kind of invariants – i.e., some acoustic property that, for each sound, uniquely identifies it as being that particular sound. That is, there might be some core acoustic property, or properties, that is essential to speech perception. However, despite decades of research, very few invariant properties in the speech signal have been found. As Nygaard and Pisoni (1995) put it:
At first glance, the solution to the problem of how we perceive speech seems deceptively simple. If one could identify stretches of the acoustic waveform that correspond to units of perception, then the path from sound to meaning would be clear. However, this correspondence or mapping has proven extremely difficult to find, even after some forty-five years of research on the problem.
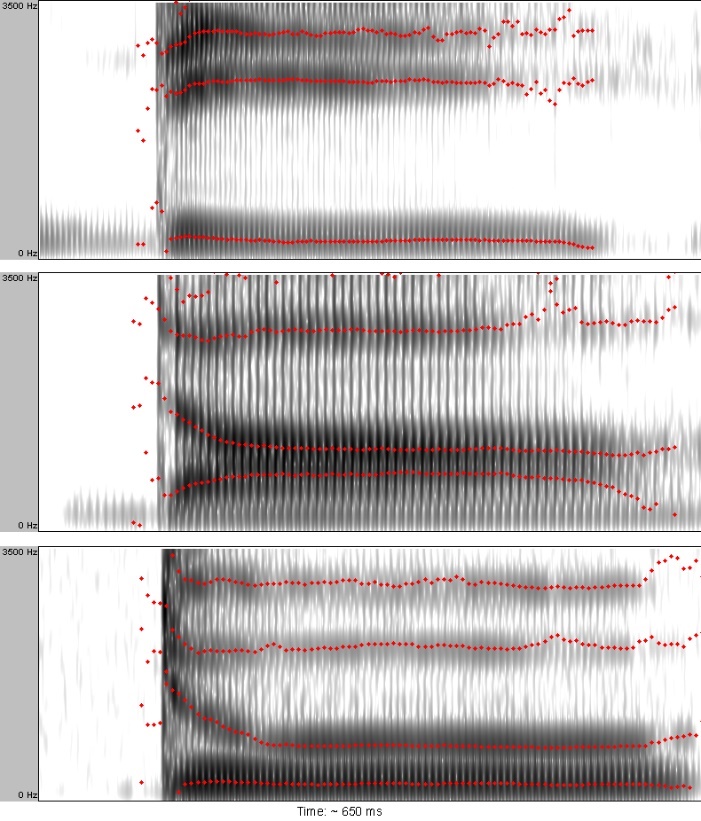
This reflects both a one-to-many and a many-to-one problem. The one-to-many problem is that a particular acoustic aspect of the speech signal can cue multiple different linguistically relevant dimensions. For example, the duration of a vowel in English can indicate whether or not the vowel is stressed, or whether it is in a syllable closed by (~ending with) a voiced or a voiceless consonant, and in some cases (like American English /ɛ/ and /æ/) it can distinguish the identity of vowels (Klatt, 1976). A second reason is the converse, a many-to-one problem: a particular linguistic unit can be cued by several different acoustic properties. For example, the figure below shows how the onset formant transitions of /d/ differ depending on the following vowel but they are all interpreted as the phoneme /d/ by listeners (Liberman, 1957).
Lack of Invariance
This lack of acoustic invariants in the speech signal is often referred to as the lack of invariance problem: there appear to be no (or at least few) reliable constant relations between a phoneme and its acoustic manifestation. There are several reasons for this:
Variation due to linguistic context
The surrounding linguistic context influences the realization of a given speech sound, such that speech sounds are influenced by (and become more like) preceding and/or following speech sounds. This is termed coarticulation (i.e., because aspects of different sounds are being articulated concurrently).
Variation due to different speakers
The resulting acoustic structure of concrete speech productions depends on the physical and psychological properties of individual speakers. For example, men, women, and children generally produce voices having different pitch. Because speakers have vocal tracts of different sizes (due to sex and age especially) the resonant frequencies (formants), which are important for recognition of speech sounds, will vary in their absolute values across individuals (Hillenbrand et al., 1995). Research shows that infants at the age of 7.5 months cannot recognize information presented by speakers of different genders; however by the age of 10.5 months, they can detect the similarities (Houston et al., 2000). Dialect and foreign accent can also cause variation, as can the social characteristics of the speaker and listener (Hay & Drager, 2010).
Linearity and the segmentation problem
On top of the lack of invariance of individual speech sounds, we somehow must be able to parse a continuous speech signal into discrete units like phonemes and words. However, although listeners perceive speech as a stream of discrete units (phonemes, syllables, and words), this linearity is difficult to see in the physical speech signal (see the figure below for an example). Speech sounds do not strictly follow one another, rather, they overlap (Fowler, 1995). That is, perception of a speech sound is influenced by the sounds that precede and the ones that follow. This influence can even be exerted at a distance of two or more segments (and across syllable- and word-boundaries).
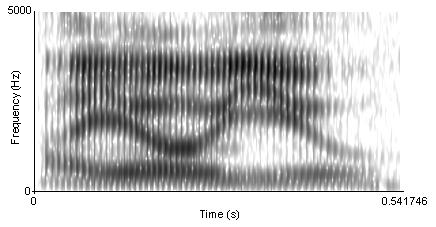
Because the speech signal is not linear, this leads to the segmentation problem. It is difficult to delimit a stretch of speech signal as belonging to a single perceptual unit. Instead, the acoustic properties of phonemes blend together and depend on the context (because, e.g., of coarticulation, discussed above).
Although we still do not know exactly how we overcome the lack of invariance and segmentation problems, we get some help from categorical perception and top-down influences on perception.
Categorical perception
Categorical perception is involved in processes of perceptual differentiation. People perceive (some) speech sounds categorically in that they are more likely to notice the differences between categories (phonemes) than within categories. The perceptual space between categories is therefore warped, the centers of categories (or “prototypes”) working a bit like magnets for incoming speech sounds (Iverson & Kuhl, 1995).
Put another way, speakers of a given language treat some categories of sounds alike (as belonging to the same phoneme category – thus categorical perception). One consequence of this is that speakers of different languages notice the difference between some phonemes but not others. English speakers can easily differentiate the /r/ phoneme from the /l/ phoneme, and thus rake and lake are heard as different words. In Japanese, however, /r/ and /l/ are variants of the same phoneme, and thus speakers of that language do not automatically categorize the words rake and lake as different words. Try saying the words cool and keep out loud. Can you hear the difference between the two /k/ sounds? To English speakers they both sound the same, but to speakers of Arabic these represent two different phonemes.

We can explore categorical perception in speech by making an artificial continuum between /p/ and /b/ speech sounds. These sounds represent a distinction between voiceless (e.g. without vibrating your vocal cords as with a whisper) and voiced “bilabial plosives” (stop consonants made by blocking the flow of air with both lips). Such sounds can be manipulated so that each item on a continuum differs from the preceding one in the amount of voice onset time or VOT. VOT refers to the length of time between the release of a stop consonant and the start of vibration of the vocal cords.
The first sound is a pre-voiced /b/, i.e. it has a negative VOT. Then, increasing the VOT, it reaches zero and the plosive becomes a plain unaspirated voiceless /p/. Gradually, adding the same amount of VOT at a time, the plosive is eventually a strongly aspirated voiceless bilabial /pʰ/. In this continuum of, for example, seven sounds, native English listeners will typically identify the first three sounds as /b/ and the last three sounds as /p/ with a clear boundary between the two categories (& Abramson, 1970). A two-alternative identification (or categorization) test will yield a discontinuous categorization function (see red curve in the Figure above). This suggests that listeners will have different sensitivity to the same relative increase in VOT depending on whether or not the boundary between categories was crossed. Similar perceptual adjustment is attested for other acoustic cues as well.
Top-down Influences
In a classic experiment, Warren (1970) replaced one phoneme of a word with a cough-like sound. Perceptually, his subjects restored the missing speech sound without any difficulty and could not accurately identify which phoneme had been disturbed, a phenomenon known as the phonemic restoration effect. An example of this phenomenon can be experienced through the video below. A related finding from reading research is that accuracy in identifying letters is greater in a word context than when in isolation (the word superiority effect; Reicher, 1969; Wheeler, 1970).
To probe the influence of semantic knowledge on perception, Garnes and Bond (1976) used carrier sentences where target words only differed in a single phoneme (bay/day/gay, for example) whose quality changed along a continuum. When put into different sentences that each naturally led to one interpretation, listeners tended to judge ambiguous words according to the meaning of the whole sentence. That is, higher-level language processes connected with morphology, syntax, or semantics may interact with basic speech perception processes to aid in recognition of speech sounds.
It may be the case that it is not necessary and maybe even not possible for a listener to recognize phonemes before recognizing higher units, like words for example. After obtaining at least a fundamental piece of information about phonemic structure of the perceived entity from the acoustic signal, listeners can compensate for missing or noise-masked phonemes using their knowledge of the spoken language. Compensatory mechanisms might even operate at the sentence level such as in learned songs, phrases, and verses (an effect backed-up by neural coding patterns consistent with the missed continuous speech fragments) despite the lack of all relevant bottom-up sensory input (Cervantes Constantino & Simon, 2018).
In language, the process through which a hearer separates speech into a sequence of identifiable words and phonemes (often without reliable breaks between words).
Broadly, the performance of one or more actions in a sequence varies according to the other actions in the sequence. In language, the formation of speech sounds may vary according to the sounds immediately preceding or following them.
Information processing in which higher level knowledge, expectations, and concepts influence the processing of lower level (e.g. sensory) information.
The length of time between the release of a stop consonant and the start of vibration of the vocal cords
A psycholinguistic phenomenon whereby a person listening to speech in which phonemes have been made inaudible does not notice the interruption.
A phenomenon describing how people are better able to recognize letters when they are presented within words as opposed to when they are presented alone or within non-word strings.
Information processing in which incoming sensory data initiate the higher level processes involved in their recognition, interpretation, and categorization.
